Coding Agents War: Does The Rising Star Claude Sonnet 4.5 Lead the Autonomous Development Race?
Trinh Nguyen
Technical/Content Writer
Home>Blog>Artificial Intelligence> Coding Agents War: Does The Rising Star Claude Sonnet 4.5 Lead the Autonomous Development Race?
Anthropic launched Claude Sonnet 4.5 on Oct 29. It proved to be one of the best AI agents for coding and computer use. This release marks a major acceleration in the AI agents race, along with OpenAI’s GPT-5 and Google’s Gemini 2.5 Pro and other next-generation models.
Claude Sonnet 4.5 isn’t simply a minor update, but a high jump in agentic capability. The model is backed by high scores on crucial coding tests and the impressive promise of 30 hours of continuous, autonomous work.
The question is no longer “Can AI code?” but “Which AI will lead the project?” This article will answer the central question: “Does Sonnet 4.5’s unprecedented endurance and performance make it the new frontrunner in the autonomous development race?”
Let’s explore together.
The Key Coding AI Agent Players
As mentioned, the AI coding arena is heating up, and several models have appeared as frontrunners.
Gemini 2.5 Pro is Google’s flagship release. It’s part of the Google ecosystem and praised for handling multiple tasks with ease. Beyond raw coding skills, Gemini excels at integrating with productivity tools kike Google Cloud, Docs, etc.
It would be a huge oversight not to mention GPT 5 Codex, OpenAI’s latest coding specialist. The model is trained extensively on programming data and built to deliver flexible, developer-friendly API support. Its strength lies in adaptability: from debugging legacy systems to generating complex software architectures. Codex is designed as a versatile co-pilot for developers of all levels.
Today we have Claude Sonnet 4.5. Anthropic’s mid-sized model strikes a balance between power and efficiency, with a strong focus on safety, memory, and staying locked on long-term tasks. Early adopters highlight its ability to sustain multi-hour projects without losing track, making it especially appealing for enterprise workflows and research settings.
Claude Sonnet 4.5’s Endurance and Memory
Anthropic claims the most impressive capability of Claude Sonnet 4.5, its ability to operate independently for extended periods. It graduates AI from a session-based assistant to a true long-haul digital partner.
The 30-Hour Autonomous Leap
The headline feature, the claim that Sonnet 4.5 can maintain focus and performance for 30+ hours of autonomous operation, isn’t simply an incremental improvement. It’s an entirely new dimension of capability. Prior agent models, including Anthropic’s own earlier versions, often suffered from “context fatigue”: they would lose track of the original goal, drift off course, or simply stop functioning after a few hours or a certain number of steps.
Complex Refactoring: Instead of handling single-file changes, the agent can be tasked with a massive codebase overhaul, tracking dependency changes and ensuring consistency across thousands of lines over several simulated workdays.
Multi-Day Debugging: The model can sustain deep-seated, intermittent bug hunts, treating the entire debugging process as a single, multi-step problem rather than a series of disconnected prompts.
End-to-End Feature Implementation: A developer can assign a complex user story, such as “Implement a secure payment gateway,” and the agent can manage the planning, coding, testing, and file creation with minimal check-ins, delivering a feature instead of just a function.
This is the distinction between a helpful intern who needs constant supervision and a junior engineer who can own a task until completion.
Complex Management and Memory Tools
Achieving this marathon focus required a complete re-engineering of how the model handles information. The ability to endure 30 hours is rooted in technical advancements that fundamentally solve the problem of context drift.
Context Awareness and Token Optimization
Sonnet 4.5 is far more efficient in its use of its context window. It doesn’t treat every piece of information equally. The model is equipped with an internal mechanism to track its token usage throughout the conversation and tool calls. This awareness allows it to recognize when it’s approaching memory limits, enabling it to prioritize the most relevant project details and effectively clear stale context to make room for new, critical information. This prevents the frustrating “task abandonment” seen in earlier models that would simply crash or hallucinate when their memory buffer was exceeded.
The New Memory Tool and State Tracking
For truly long-running agents, not all information can live inside the immediate context window. The API’s new Memory Tool allows the agent system to store and consult long-term project information externally. This external storage acts like a project binder, preserving the essential goals, architecture decisions, and code patterns across sessions. This capability ensures that even if the agent is interrupted or moves to a separate task, it can return and maintain coherence and goal-orientation without having to be re-prompted with the entire history.
Checkpoints for Trust and Control
To give developers confidence in these long autonomous runs, Anthropic introduced the Checkpoint feature for Claude Code. This allows the agent to instantly save the state of the work at critical junctures. If an autonomous run goes off the rails, a possibility in any complex coding task, the developer can roll back instantly to a known stable point, preventing the waste of hours of compute time and effort. This feature manages the risk of high-autonomy agents, making them reliable enough for production workflows.
Leading the Benchmarks: Pure Code Performance
While the 30+ hours prove endurance, the question of leadership often comes down to raw intelligence. Sonnet 4.5 performance on industry evaluations confirms Anthropic’s claim that it’s one of the best coding models available, even challenging their own premium offerings.
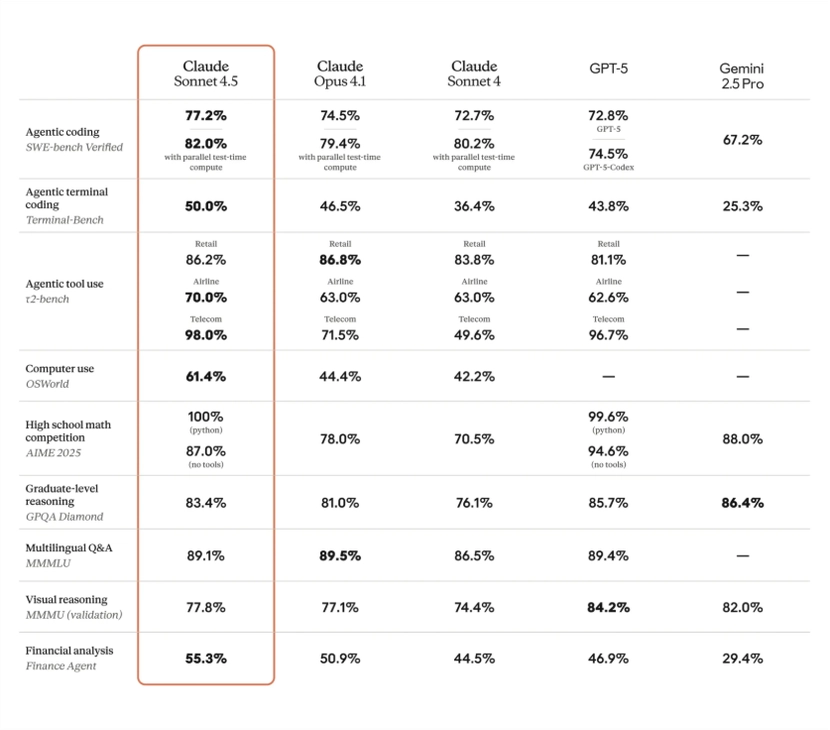
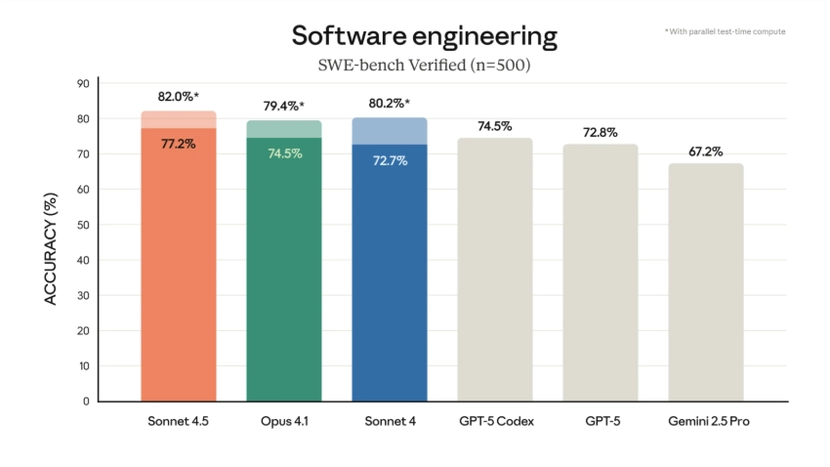
The SWE-Bench Verified Challenge
SWE-Bench Verified benchmark measures an AI’s ability to solve real-world software engineering issues, bugs, and features pulled directly from popular open-source repositories. To pass, the model must not just suggest code, but successfully apply a fix and pass the corresponding tests.
Sonnet 4.5’s top performance on SWE-Bench Verified indicates a genuine proficiency in handling technical debt, complex debugging, and making context-aware changes to existing codebases. It demonstrates the ability to act as a practical contributor to a team, not just a theoretical one.
Developer Reality Check
While the benchmarks are glowing, early developer feedback provides a healthy dose of reality. Sonnet 4.5 is undeniably excellent at backend logic, technical analysis, and complex data manipulation. It writes clean functions, handles API integration well, and excels at solving clear-cut coding problems.
However, the model still shows limitations in highly subjective or visual tasks:
UI/UX Design: When asked to create visually appealing or complex front-end components, the code generated may lack modern design patterns or visual flair, often requiring significant human refinement.
Visual Consistency: In tasks involving intricate 3D graphics or nuanced front-end styling, the model can struggle to achieve the pixel-perfect consistency expected by designers.
Ultimately, the consensus is that Sonnet 4.5 is a phenomenal engineer for “what to do” (the logic). Still, human developers remain the superior architects for “how it should look” (the design and visual experience). The model is great for development, but it does not yet eliminate the need for human judgment and aesthetic taste.
The Agent SDK Developer Ecosystem
Anthropic has ensured that the revolutionary power driving Sonnet 4.5’s performance isn’t locked away in a black box. A critical piece of the release for developers is the new Claude Agent SDK (Software Development Kit).
This SDK provides access to Anthropic’s internal infrastructure to the outside world. It allows external developers to tap into the very same core tools, memory management systems, and context frameworks that power Claude Code itself.
Democratizing Agent Capabilities: Before, a developer could only access the model’s raw intelligence via the standard API. Now, the SDK provides the scaffolding needed to easily manage multi-step tasks. Developers no longer have to waste time building complex systems just to manage an AI agent’s memory or track its progress; they can focus entirely on the specific business goal they want the agent to achieve.
Building Custom, Long-Haul Agents: This infrastructure is essential for creating robust, custom AI agents. For example, a company could build a dedicated “Financial Compliance Agent” that uses the SDK’s tools to monitor 30 hours’ worth of regulatory feeds, automatically cross-reference internal documents, and generate a compliance report, all while using the same reliable context-tracking that powers Sonnet 4.5.
Accelerating the Ecosystem: By sharing its core agent infrastructure, Anthropic encourages a vast ecosystem of third-party, specialized agents. This moves the industry past simple prompt engineering and toward true AI system design, where developers use Sonnet 4.5 as a reliable brain inside their own, highly complex automated solutions.
The Road Ahead of Coding Agents
It’s clear that Claude Sonnet 4.5 is the new gold standard for sustained autonomous execution.
While rivals like GPT-5 and Gemini 2.5 Pro compete fiercely on speed and raw intelligence, Sonnet 4.5’s breakthrough – the ability to maintain focus for over 30 hours – solves the critical context fatigue problem. This makes it the leading platform for tackling large-scale, real-world engineering projects. When measured by its ability to reliably deliver a completed, multi-step project without human intervention, Sonnet 4.5 is setting the pace.
This progress fundamentally changes the engineer’s role. With agents handling the tedious, long-haul work of refactoring and debugging, human engineers become AI Governors and architects. Their focus shifts from writing every line of code to setting high-level goals, validating the agent’s output, and innovating on system design. The Coding Agent War is now about which platform, armed with tools like the Claude Agent SDK, can most reliably translate complex human intent into finished software. For now, Anthropic has secured a significant lead in that new frontier.
I'm Trinh Nguyen, a passionate content writer at Neurond, a leading AI company in Vietnam. Fueled by a love of storytelling and technology, I craft engaging articles that demystify the world of AI and Data. With a keen eye for detail and a knack for SEO, I ensure my content is both informative and discoverable. When I'm not immersed in the latest AI trends, you can find me exploring new hobbies or binge-watching sci-fi
Content Map Heal the Inner Child Social and Emotional Drivers The Technology Behind: AI and the Democratization of Creativity How to Create a “Hug My Younger Self” AI Image Time to Hug Your Younger Self Scroll through social media today, and you’ll see an image that is both technical and deeply emotional: a person’s current adult self giving a tender […]