Efficient, private, and responsive generative AI is no longer a distant ideal for personal computers. With Neurond’s strategic integration of Intel’s OpenVINO, enterprises can now scale large language models (LLMs) directly on Core Ultra CPUs and Arc GPUs, transforming how AI is deployed, accessed, and experienced on the desktop. This practical synergy not only unlocks the full capacity of modern Intel hardware but also sets a new standard for speed, versatility, and user control in enterprise and developer environments.
Scaling Local LLMs with OpenVINO LLM
Deploying advanced generative models locally isn’t simply a matter of preference; it’s a strategic necessity. OpenVINO GenAI technology, optimized for Intel’s latest CPUs and GPUs, brings this vision to fruition.
Benefits of Local LLM Deployment
Running language models and generative AI locally on Intel-powered systems brings immediate, tangible advantages. Unlike cloud-based solutions, local LLMs deliver enhanced privacy, ensuring that sensitive data remains on-device and is never transmitted externally. This is particularly relevant for regulated industries and enterprise teams concerned about data sovereignty or compliance.
Moreover, local deployment slashes response times. Users experience near-instantaneous AI-generated results, sidestepping the latency and unpredictability of remote servers. Being device-resident also means these solutions function offline, an essential benefit for distributed teams or mobile professionals needing uninterrupted access to advanced text generation and image generation capabilities.
OpenVINO Toolkit Advantages for LLMs
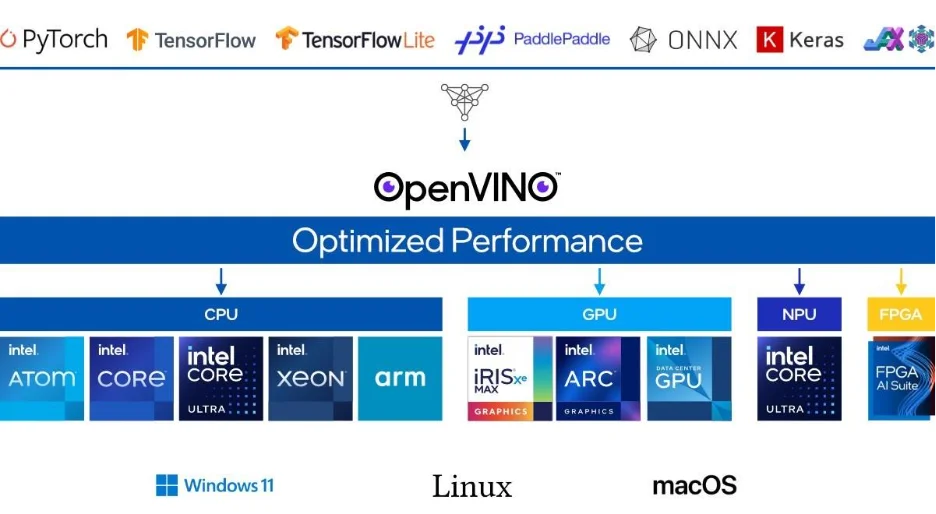
The OpenVINO toolkit stands out as a robust, open-source platform for optimizing and deploying AI workloads. When it comes to running an AI model – specifically LLM models – the toolkit maximizes hardware utilization. Features such as dynamic quantization, precision optimization, and support for various hardware backends (CPU, GPU, NPU) enable enterprises to achieve optimal inference latency and performance without sacrificing accuracy.
For developers, OpenVINO offers a simple interface with fewer dependencies, minimizing compatibility issues and reducing setup complexity. This streamlines the process, enabling teams to run inference on models in IR format using just a local folder and the right OpenVINO runtime, no heavyweight frameworks needed.
Why Core Ultra and Arc Matter
Intel’s Core Ultra CPUs and Arc GPUs represent a leap forward for on-device AI. According to recent insights, “Intel has powered the majority of personal computers for decades, and the Core Ultra generation adds built-in AI acceleration that makes on-device LLMs practical.” With dedicated AI acceleration, these platforms deliver the raw performance and efficiency necessary for scaling modern LLMs, especially when paired with OpenVINO’s model optimization capabilities.
Arc GPUs, in particular, unlock unprecedented speed for both inference and generative tasks. They excel at handling high-throughput demands, significantly reducing inference latency and enabling seamless, real-time applications that previously required cloud hardware.
Optimizing Local OpenVINO Model Performance
Efficient LLMs deployment on personal computers hinges on model optimization: reducing memory demands, speeding up computation, and maintaining quality output across hardware.
Quantization Methods for Efficient Inference
Quantization transforms standard deep learning models into lightweight, hyper-efficient versions suitable for local use. By reducing model parameters from floating point to lower-precision formats (e.g., INT4), OpenVINO enables rapid, low-power AI inference without significant loss in generative quality. Dynamic quantization applied at runtime further optimizes resource use based on current hardware, ensuring robust performance whether on CPU, GPU, or NPU.
This process is particularly vital when deploying large models in environments with tight memory constraints. Effective quantization not only accelerates inference but also enables running models that would otherwise be too large for local hardware.
Reducing Model Footprint and Memory Use
One of the chief challenges users face is managing big model downloads and memory usage when multitasking or operating on resource-constrained devices. OpenVINO addresses this by converting models to a compact IR format, minimizing model footprint and facilitating smoother execution even when multiple processes share the same hardware.
This efficiency translates to real-world savings in energy, heat, and device wear, ultimately resulting in quieter systems with less frequent fan noise or battery drain during intensive deep learning operations.
Dynamic Quantization and KV Caching Strategies
Advanced LLM implementations utilize techniques like KV cache and prefix caching to trim inference times and memory consumption further. These tactics allow partial reuse of processed data, speeding up each new text or image generation request. For developers, these features are crucial for building scalable text generation applications and dynamic conversational agents that respond fluidly, without lag.
Once adapting quantization strategies, OpenVINO ensures that models remain both responsive and resource-aware, regardless of the hardware backend. This adaptability marks a significant leap forward in deploying generative AI that feels truly native and integrated.
Neurond Approach to Generative Models on Intel
Neurond streamlines every phase of the local LLM workflow from model preparation and conversion to production-level serving and API integration.
Model Preparation and IR Format Conversion
Before deployment, Neurond employs advanced techniques to quantize and convert AI models into the OpenVINO IR format. As described in the most searched data, “Neurond quantizes and converts models to OpenVINO IR (using Optimum) and then serves them through OpenVINO Model Server.” This step slashes model size and tailors the model precisely to the intricacies of Intel hardware, enabling teams to deploy models without extensive re-engineering or dependency headaches.
Serving Models Using OpenVINO Model Server
Once optimized, models are hosted via OpenVINO Model Server, a fast, scalable solution that abstracts away low-level details. This setup allows multiple users or applications to access the same model simultaneously, leveraging the underlying hardware to maximize throughput and minimize inference latency.
Serving models in this way also means enterprises can scale quickly, adding more models or users as needed without rearchitecting the deployment pipeline. OpenVINO supports a broad variety of generative and computer vision models, ensuring compatibility with enterprise use cases ranging from document analysis to dynamic image creation.
Connecting via OpenAI Compatible API
Flexibility for developers is critical. Through an OpenAI-compatible API exposed by OpenVINO Model Server, applications connect over REST or gRPC, allowing seamless integration across programming languages and platforms. This approach means that both in-house and third-party apps can plug into enterprise LLM infrastructure with minimal friction, speeding pilots and reducing development cycles.
Neurond’s approach here is simple and repeatable, allowing teams to focus on creating value rather than wrestling with infrastructure complexity.
Performance Benchmarks on Core Ultra and Arc
Hard data matters for executives evaluating infrastructure decisions. Neurond rigorously benchmarks OpenVINO LLM deployments across Intel’s latest hardware, delivering transparent metrics that inform real-world performance and ROI calculations.
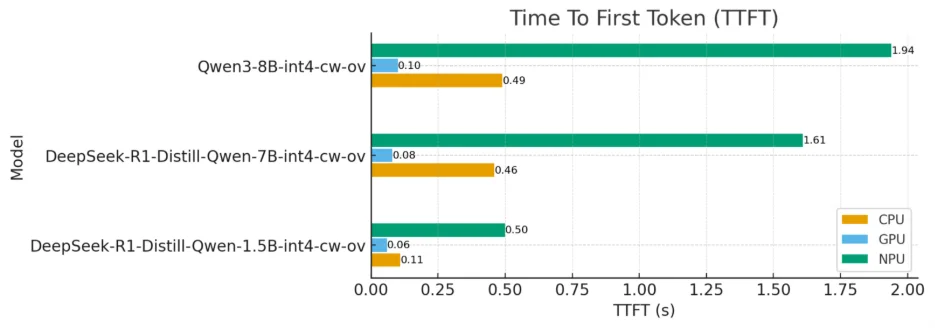
Time to First Token TTFT Comparisons
Responsiveness is measured by Time-to-First-Token (TTFT), an essential indicator of user experience. Neurond’s tests reveal that Arc GPUs delivered the lowest TTFT; CPUs were moderate; NPUs had the highest startup latency and were less ideal for interactive use. For instance, for a 1.5B parameter model, the TTFT was approximately 0.06 seconds on the GPU versus 0.34 seconds on the CPU and 0.27 seconds on the NPU, a compelling demonstration of GPU advantage for interactive workloads.
Benchmark result: Time to First Token of different models on three devices
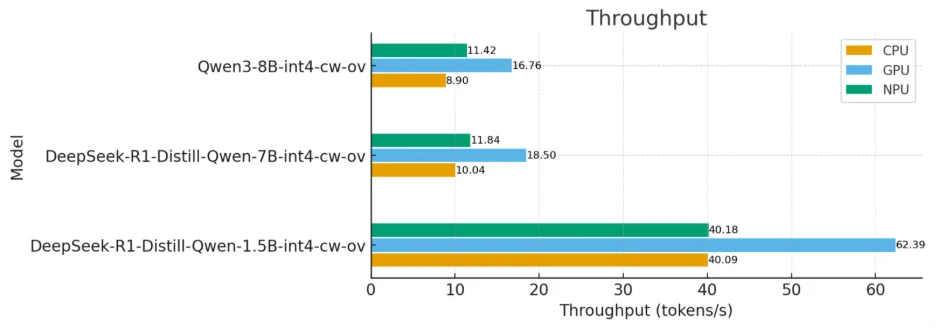
Throughput Analysis across Devices
When it comes to sustained speed, throughput (tokens per second) is king. In Neurond’s measurements, “the GPU led throughput across model sizes for example, a 1.5B model reached ~62.4 tokens/s on GPU, with CPU and NPU about 35% lower.” These results underscore the advantage of leveraging Arc GPUs for high-volume or real-time text generation and generative AI tasks.
Benchmark result: Throughput of different models on three devices
Device Recommendations for Best Results
With these benchmarks in mind, Neurond recommends “the GPU as the best default for both latency and throughput; the NPU currently trails on latency for real-time tasks.” For demanding interactive scenarios, executives should prioritize Arc GPU-backed deployments while CPUs and NPUs provide value as fallback or batch-processing solutions.
Practical Benefits for Private Generative AI
The real-world impact of scaling local LLMs with OpenVINO and Intel is measured by privacy, cost, and simplicity.
Enhanced Privacy vs. Cloud AI Services
Running LLMs locally means sensitive data never leaves the device. As one FAQ puts it, “Local LLMs offer stronger privacy, faster responses, and offline capability without sending data to the cloud.” This is a game-changer for sectors where confidentiality, data protection, and regulatory compliance rules.
Cost Savings and Offline Capability
Enterprises that deploy LLMs on existing Intel hardware dramatically reduce their cloud AI expenses. Private, responsive AI becomes accessible to all team members regardless of network conditions or internet outages. This approach also future-proofs workflows against changes in cloud vendor pricing or policy.
Fewer Dependencies and Simple Interface
A major pain point in deploying LLMs is dependency management. OpenVINO’s simple interface and minimized dependency tree make it easy to install and run locally, speeding time to value and lowering maintenance overhead. Teams spend less time on environment setup and more on driving business outcomes with cutting-edge generative models.
Developer Workflow for OpenVINO Deployment
Streamlined, reproducible processes are essential for enterprise scalability. The Neurond–OpenVINO pipeline is engineered for clarity and repeatability at every step.
1. Exporting Models with Optimum CLI Tools
Using the optimum Intel CLI, developers export trained models directly to OpenVINO’s IR format. This automated tool bridges the gap between model design in frameworks like Hugging Face Transformers and Intel’s optimized execution layer, making conversion simple even for complex language model architectures.
2. Setting up and Running Local Inference
With the optimized model in hand, teams leverage OpenVINO Model Server to serve and manage LLMs. The workflow optimize, serve, connect removes guesswork and ensures that each model is ready for high-performance inference with no surprises. Built-in support for Python APIs and fewer dependencies allows rapid prototyping and deployment, further streamlining the process from development to production.
3. Integrating with Neurond Assistant
By serving models through OpenVINO Model Server, Neurond Assistant, and related products, users can access powerful, optimized large language models directly, unlocking seamless integration with existing workflows and applications. This tight integration supports organizational agility and accelerates time-to-market for new AI-powered features.
As the landscape of on-device AI evolves, so too does Neurond’s vision for pushing the frontier of enterprise generative AI.
Extending Context Length and Capabilities
The next phase of optimization focuses on increasing context window sizes. Extended context enhances the quality of text generation and complex reasoning, benefiting use cases from document understanding to conversational AI. Ongoing research in OpenVINO techniques promises further gains in model adaptability and content richness.
Conclusion
The partnership between Neurond and Intel, fueled by OpenVINO, marks a defining moment for on-device generative AI. Enterprises can now deploy sophisticated, high-performance LLMs securely and efficiently on familiar Intel-powered infrastructure, ushering in new possibilities for privacy, responsiveness, and scalability.
Key takeaways include the game-changing benefits of OpenVINO’s deep learning optimizations, practical workflows for scaling local LLMs, and transparent performance benchmarks that illuminate the best device choices for varied workloads. This approach delivers on the promise of private, cost-effective AI without compromise.
Trinh Nguyen
I'm Trinh Nguyen, a passionate content writer at Neurond, a leading AI company in Vietnam. Fueled by a love of storytelling and technology, I craft engaging articles that demystify the world of AI and Data. With a keen eye for detail and a knack for SEO, I ensure my content is both informative and discoverable. When I'm not immersed in the latest AI trends, you can find me exploring new hobbies or binge-watching sci-fi
On June 22, 2025, the fourth “Top Industry 4.0 Vietnam – Industry 4.0 Awards 2025” ceremony was solemnly held at the Hanoi Military Theater. The program is part of a series of activities to implement Resolution No. 57-NQ/TW dated December 22, 2024 of the Politburo on breakthroughs in science, technology, innovation, and national digital […]