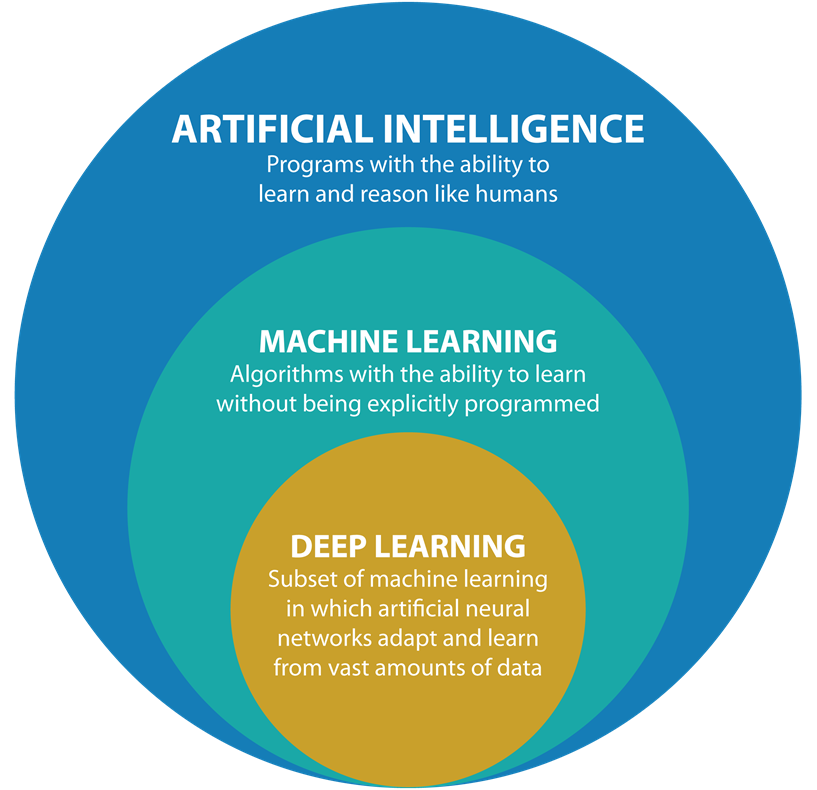
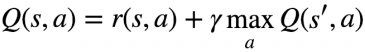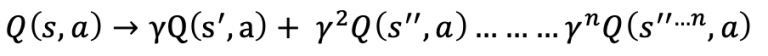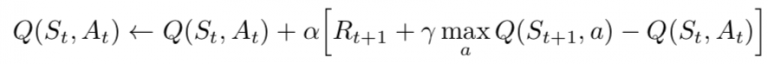Machine Learning is a subset of Artificial Intelligence. It include supervisor learning, unsupervised learning, reinforcement learning and their combination. Since the ideas of artificial neural network, a subset of machine learning called Deep Learning, using neural network, was born.
Artificial Intelligence.
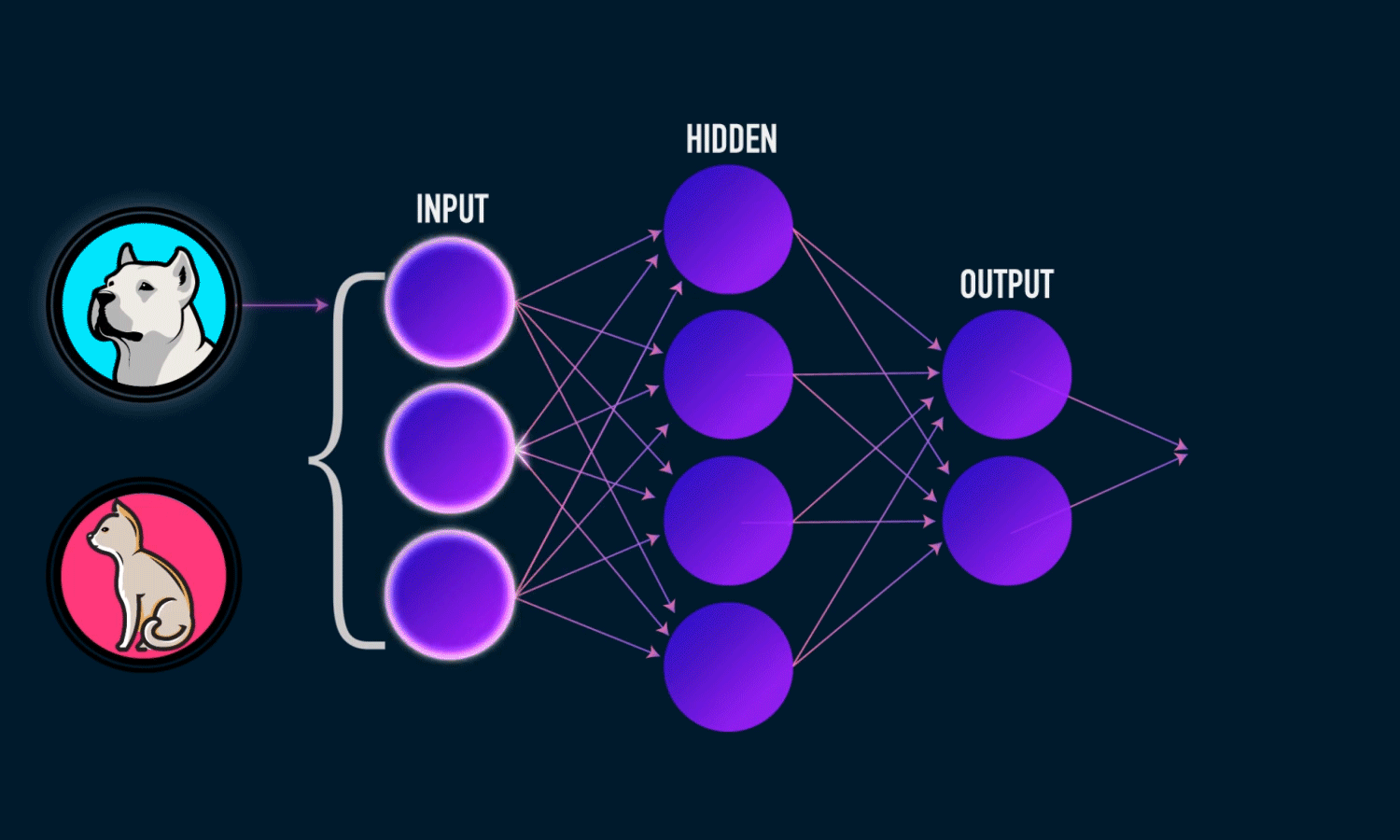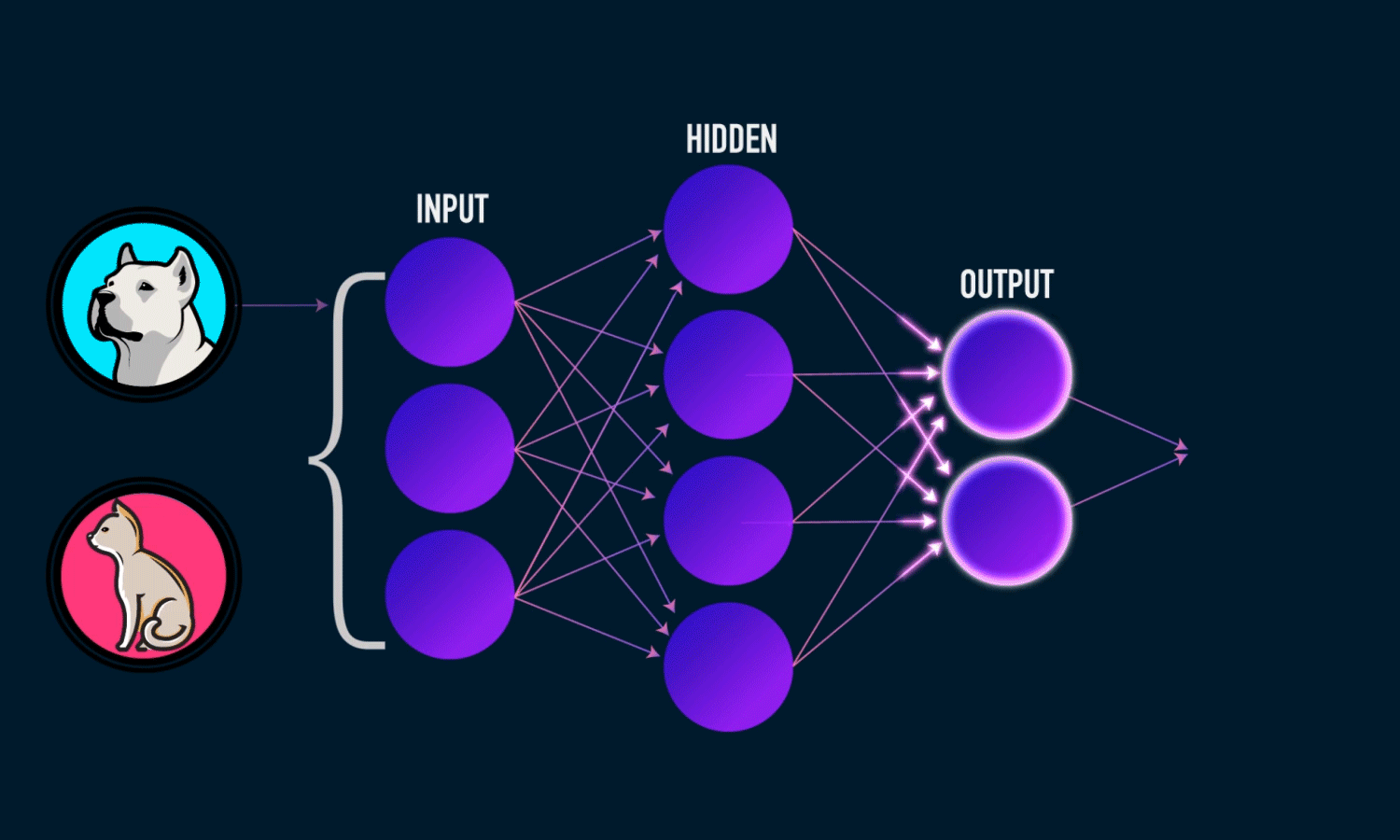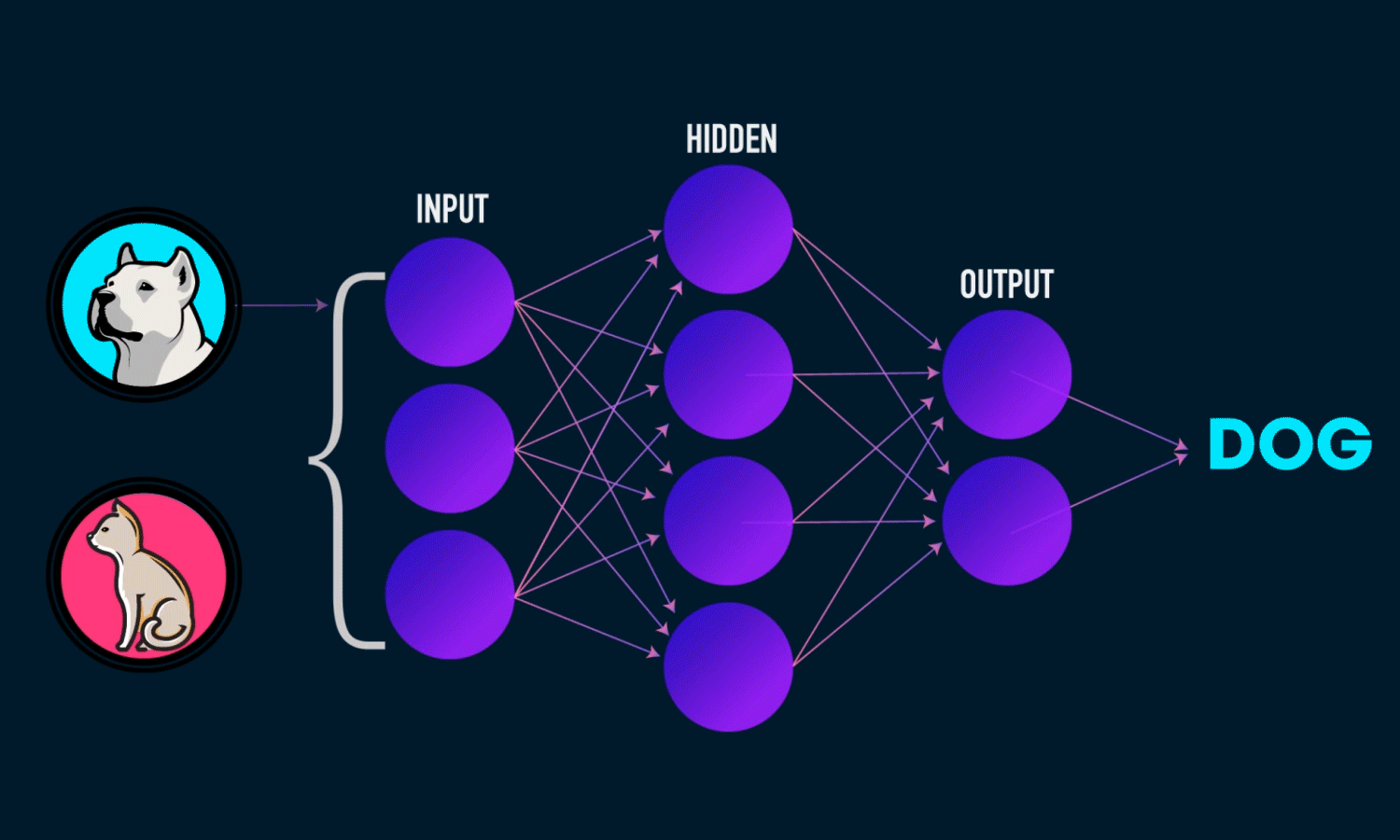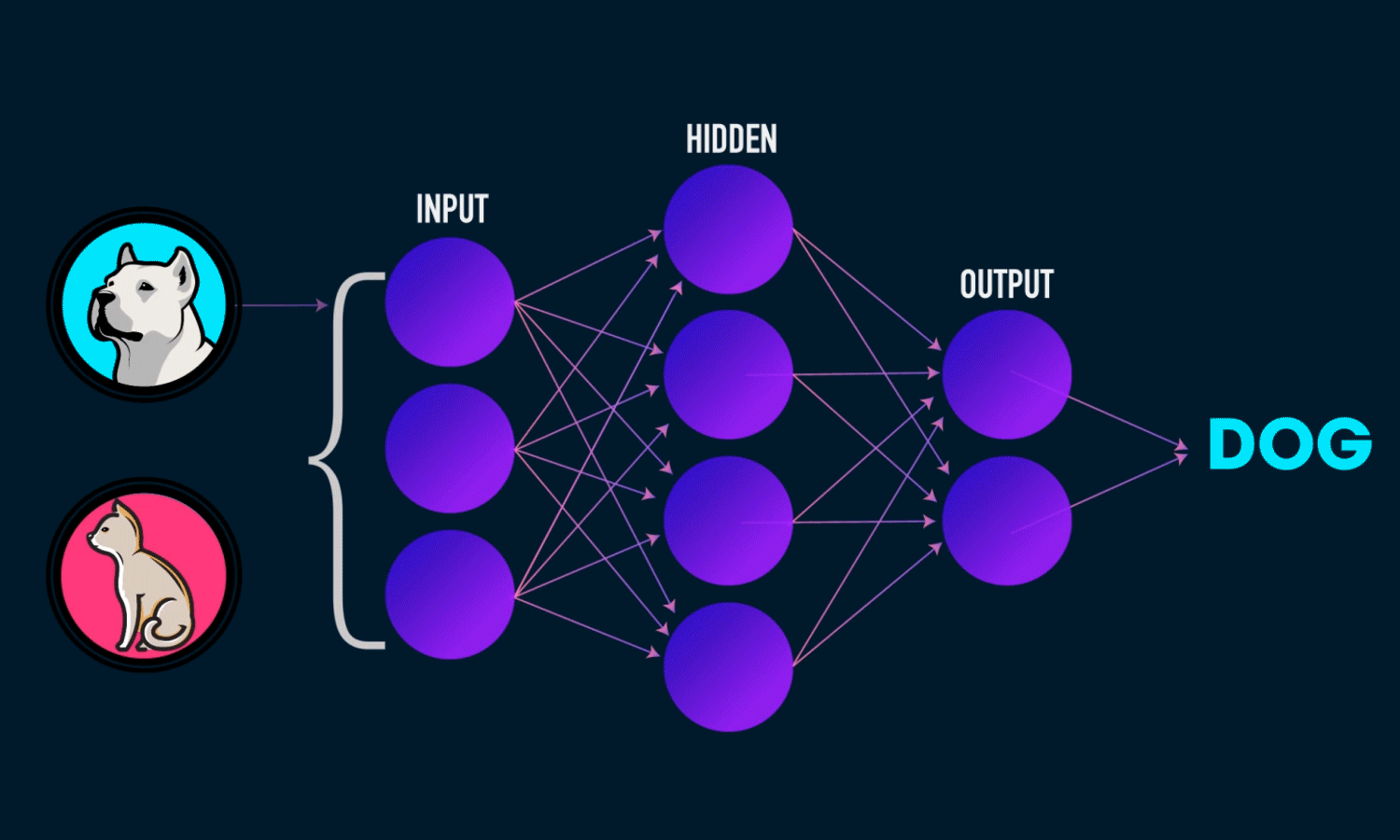
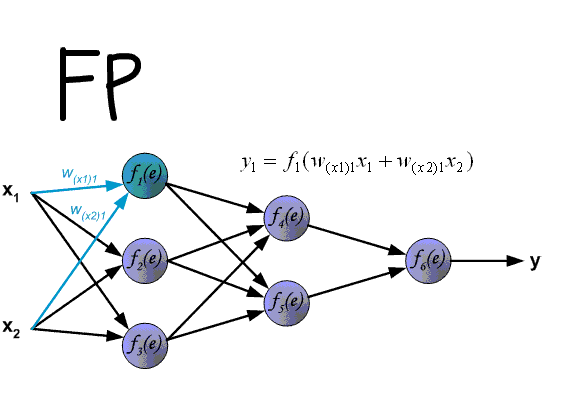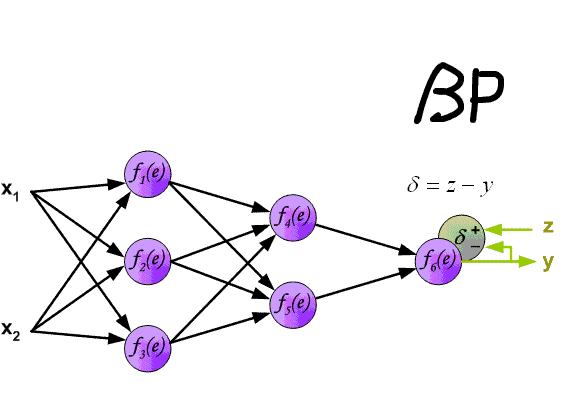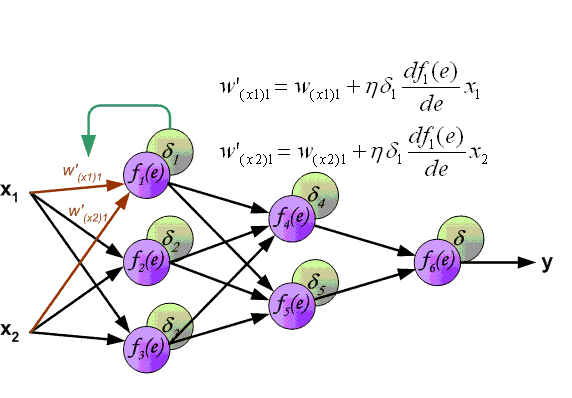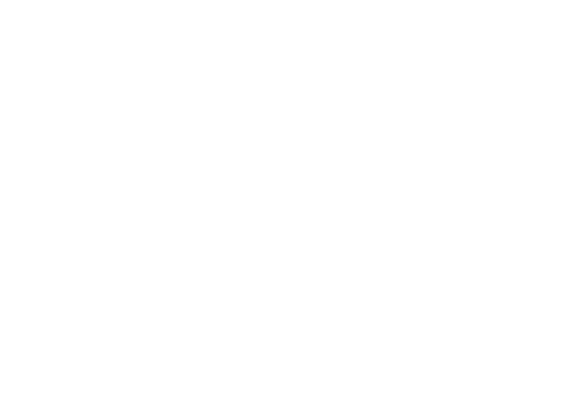
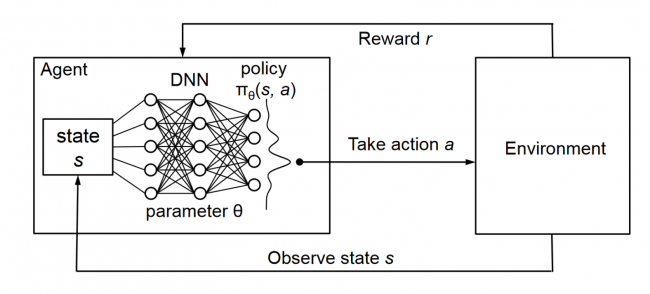
Let’s talk about Deep Learning first, it use neural network to see how “important” the input effect desired output. A simple fully-connected neural network has 3 layers: input, output and hidden layer, all in numberic form. Input provides neural network the “vision”, the important features that effect the output. The output layer can be one value, or multidimension vector. Each node has its weight and bias.
Let’s consider a problem: Get the picture of and predict the type of animal in that picture.
We need to find the input picture is a dog or a cat, so the output should be in 2 dimensions, one for dog and one for cat. We will label [1 0] for dog and [0 1] for cat.
The network will “learn” through back propagation and chain rules. To “learn” how “important” the input effect desired output, we need to update weights and bias, by error. An error is the difference between output and desired value. Feed forward is a model for prediction, but neural network will “learn” backward.
Feed forward and back propagation.
The neural network will adjust the weights and bias of each node, to self-learn the effect of input to the output based on our labelled data. Our aims is to minimize the error.
Return to machine learning, each type of learning is useful in particular problem. Machine learning use math algorithms to predict, classify, learning to minimize the error, etc.
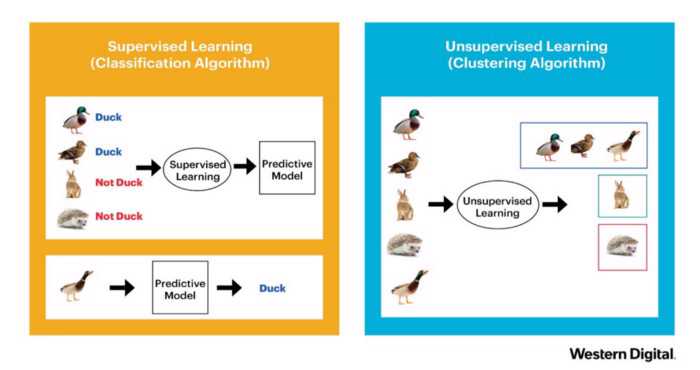
Supervised learning use labelled data or data with similar things to classify or predict the trend. In the other side, unsupervised learning isn’t provided anything, it will learn from given data. In fact, unsupervised learning is a tool to help supervised learning “understand” more about data.
Supervised and Unsupervised Learning.
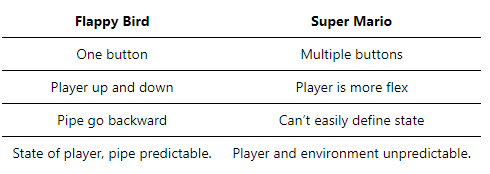
However, AI must solve more complex problem now. For example, Flappy Bird is a game that we can’t know exactly what is our desired output at a time. In addition, the game pipes is random, so we can’t fixed the value of pipe, bird,… every game. In this problem, we must use Reinforcement Learning.
Types of Machine Learning.
Fortunately, Reinforcement Learning is relevant to our life, so it is easy to understand. Reinforcement Learning is learning from mistake, without data provided. The idea of reinforcement learning is letting the bot explore the environment. We will give it some reward to tell that the bot is doing good, and also a punishment when it fail. The bot will find the ways to maximize the reward.
Now we will know more about some algorithms and neural network by working with the code.
Although we know that we can’t use only neural network to learn how to play Flappy Bird, at least we try once to see the behavior of the bird when we only use fully-connected neural network.
First, build the network by ourselves to help us easier to understand.
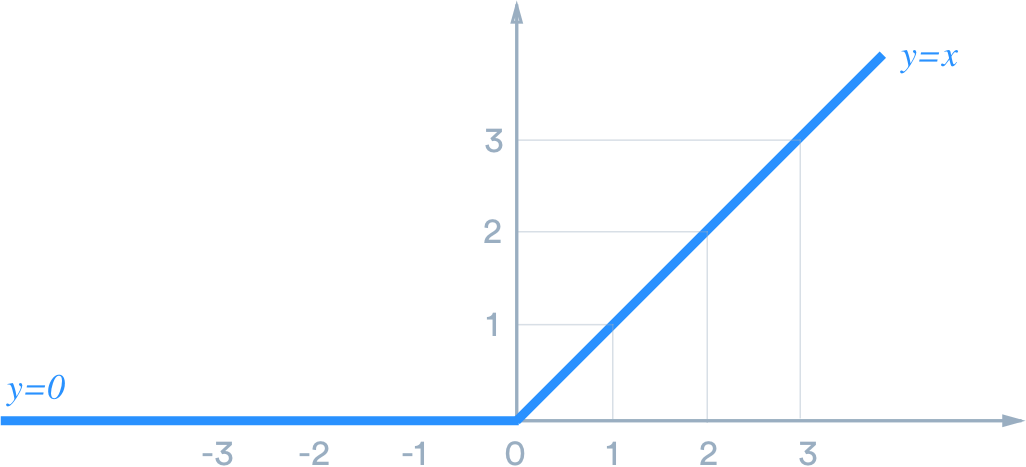
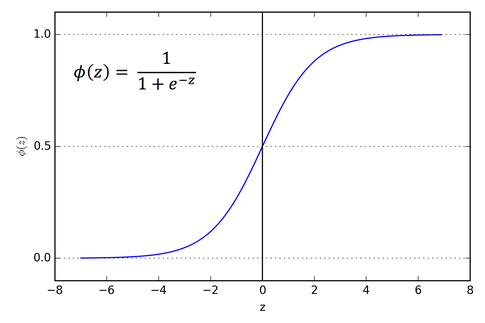
Sigmoid and ReLu is our activation function. As we see in the network, sometimes not every node is activated. In addition, we should input the value from 0 to 1 to the node.
ReLu.
Sigmoid.
As mentioned, the back propagation use chain rule, so we need the derivative of the activation function.
The neural network runs from input to output, with one hidden layer. The output of a layer is very simple thanks to neural network, the output is just dot product of input and weights, and activate by Sigmoid function.
The number of input node is 3, so let’s stop a while to see our problem with Flappy Bird.
Flappy Bird.
The input is the vertical position of next pipe, the vertical position of the following pipe, the height of the bird, and the horizontal distance from the bird to the next pipe. We have 3 input, 1 output (jump or not).
Through observation, we see that the bird movement is up and down, so the horizontal position is constant. There are always 2 column of pipes on the screen and it will move backward the screen. After the bird score one point, we imediately update the position of the following pipe. So we only need 3 input now:
The vertical position of next pipe
The distance
The height of the bird
We will normalize it as input to the neural network.
To help the neural network update value, we use derivative of Sigmoid to help the network “learn” with chain rule. We don’t have the error so let’s set the error to the middle vertical position of the “hole”.
As we know, the bird will not learn because there is not an expected output. An implement of neural network using library make the behavior worse because we can’t modify the error.
However, we strongly believe that neural network will be able to play the game with right weight set. However, we need another way to find the weight.
In this case, meta learning should work.
Definition of Wikipedia: Meta learning is a subfield of machine learning where automatic learning algorithms are applied on metadata about machine learning experiments. As of 2017 the term had not found a standard interpretation, however the main goal is to use such metadata to understand how automatic learning can become flexible in solving learning problems, hence to improve the performance of existing learning algorithms or to learn (induce) the learning algorithm itself, hence the alternative term learning to learn.
We have 3 input, 1 output and hidden layer have 7 node, using Keras, we have more readable code.
for i in range(population):\n model = Sequential()\n model.add(Dense(output_dim=7, input_dim=3))\n model.add(Activation("sigmoid"))\n model.add(Dense(output_dim=1))\n model.add(Activation("sigmoid"))\n\nsgd = SGD(lr=0.01, decay=1e-6, momentum=0.9, nesterov=True)\n model.compile(loss="mse", optimizer=sgd, metrics=["accuracy"])\n currentPool.append(model)\n fitness.append(-100)
Using Generic Learning, we follow the steps:
Step 1: Create 50 bots, each has its own neural network, and let the bot play, so we change a litte bit with neural network, we also need an array to store fitness to know which bird get the best result.
Step 2: Choose 2 bots have the best results. We know that this is the best according to fitness function. With Flappy Bird, we use the survival time.
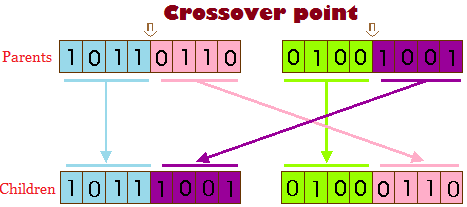
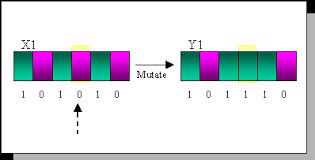
Step 3: After having 2 bots, we use their weights to generate next generation, with crossover and mutate.
Then do the step again and again to find the best weight, without back propagation.
Crossover.Mutation.
Result of Genetic Learning
Although we have decent result, the bot didn’t learn meaningful anything, we just know that if there is suitable weights and chosen parameter, the neural network will work.
So at this time, we use reinforcement learning. From observation above, we see that the position of the bird is in a range, the position pipes are also, so we try a popular implementation of Reinforcement Learning called Q learning. In addition, we use neural network, so that the next method Deep Q Learning.
As an implementation of Reinforcement Learning, Q Learning use reward and punishment to help the bot know how well it is doing. The idea depend on the state of the player, it take the state, and action as input of the Q function, and calculate Q value. The next state Q value will depend on the next stage harvested in the way of training.
Deep Q Learning.
The formula tell that Q value take the the state and action as parameter, equal to the reward function which also a function of the state, action and maximum reward of the future state, for the same action. Q(s’,a) again depends on Q(s”,a) which will then have a coefficient of gamma squared. So, the Q-value depends on Q-values of future states as shown here:
Normally, gamma is equal to 0.95 or 0.9, we will talk about gamma later. So with the idea, since this is a recursive equation, we can start with making arbitrary assumptions for all q-values. With experience, it will converge to the optimal policy. In practical situations, this is implemented as an update:
In this case, to minimize the posible state, height, we replace it with the velocity of the bird, which values in a shorter range (from integer -9 to 10), the height now is calculate in the vertical difference.
The q values will be saved as json file, look like:
"-30_20_10": [124.90673597144435, 0]
We will save the state as string, in this case, state is:
-30: distance
20: vertical difference = vertical cordination of pipe — vertical cordination of bird
10: drop velocity
The state “-30_20_10” has value [124.90673597144435, 0], that’s mean q value when it act the action jump(1) is 124.906… and not jump is 0.
Result of q learning
Q Learning characteristic
All the past experience is stored by the user in memory
The next action is determined by the maximum output of the Q-network
The loss function here is mean squared error of the predicted Q-value and the target Q-value — Q*. This is basically a regression problem. However, we do not know the target or actual value here as we are dealing with a reinforcement learning problem.
Conclusion on Q Learning
Deep Q Learning is a solution for a finite input state.
The reward is surviving as long as possible. So the bird need to survive, that’s our policy. According to the state, the bird will itself evaluates the q-value of next stage depend on all next states.
Generic network is quite good, however, there are many random fields effect our performance.
Deep reinforcement learning is good with open environment, it will explore the environment.
The problem now is when facing an infinite input environment, such as Mario and complex output, where to start?
Comparison
So next, we will use an new algorithms to make to bot play the Mario game.
Apply Reinforcement Learning in Super Mario
Thank to Elon Musk and his colleagues, OpenAI, a project of a capped-profit artificial intelligence research organization that aims to promote and develop friendly AI in such a way as to benefit humanity as a whole. OpenAI Gym is a toolkit for developing and comparing reinforcement learning algorithms. This is the gym open-source library, which gives you access to a standardized set of environments.
Asynchronous Advantage Actor-Critic Algorithms Idea
Explanation in layman’s term (Quoted from Viet Nguyen best explanation)
If you are already familiar to reinforcement learning in general and A3C in particular, you could skip this part. I write this part for explaining what is A3C algorithm, how and why it works, to people who are interested in or curious about A3C or my implementation, but do not understand the mechanism behind. Therefore, you do not need any prerequisite knowledge for reading this part ☺️
If you search on the internet, there are numerous article introducing or explaining A3C, some even provide sample code. However, I would like to take another approach: Break down the name Asynchronous Actor-Critic Agents into smaller parts and explain in an aggregated manner.
Actor-Critic
Your agent has 2 parts called actor and critic, and its goal is to make both parts perfom better over time by exploring and exploiting the environment. Let imagine a small mischievous child (actor) is discovering the amazing world around him, while his dad (critic) oversees him, to make sure that he does not do anything dangerous. Whenever the kid does anything good, his dad will praise and encourage him to repeat that action in the future. And of course, when the kid do anything harmful, he will get warning from his dad. The more the kid interact to the world, and take different actions, the more feedback, both positive and negative, he gets from his dad. The goal of the kid is, to collect as many positive feedback as possible from his dad, while the goal of the dad is to evaluate his son’s action better. In other word, we have a win-win relationship between the kid and his dad, or equivalently between actor and critic.
Advantage Actor-Critic
To make the kid learn faster, and more stable, the dad, instead of telling his son how good his action is, will tell him how better or worse his action in compared to other actions (or a “virtual” average action). An example is worth a thousand words. Let’s compare 2 pairs of dad and son. The first dad gives his son 10 candies for grade 10 and 1 candy for grade 1 in school. The second dad, on the other hand, gives his son 5 candies for grade 10, and “punish” his son by not allowing him to watch his favorite TV series for a day when he gets grade 1. How do you think? The second dad seems to be a little bit smarter, right? Indeed, you could rarely prevent bad actions, if you still “encourage” them with small reward.
Asynchronous Advantage Actor-Critic
If an agent discovers environment alone, the learning process would be slow. More seriously, the agent could be possibly bias to a particular suboptimal solution, which is undesirable. What happen if you have a bunch of agents which simultaneously discover different part of the environment and update their new obtained knowledge to one another periodically? It is exactly the idea of Asynchronous Advantage Actor-Critic. Now the kid and his mates in kindergarten have a trip to a beautiful beach (with their teacher, of course). Their task is to build a great sand castle. Different child will build different parts of the castle, supervised by the teacher. Each of them will have different task, with the same final goal is a strong and eye-catching castle. Certainly, the role of the teacher now is the same as the dad in previous example. The only difference is that the former is busier.
Now we have in our mind that we will have a global network and workers to work for contribute their own knowledge to the net.
So we will:
Create 6 workers, each workers has its own network
Create 6 evaluator for 6 workers, and 1 for global, to see how well the bot is doing
And we hope that each bot will “learn” a little from environment to contribute to our global net
Use a convolution neural network to frame as input of the A3C, we call frame state
Actor — Crictic is a model, take the frame to convolution neural network to be the input of each worker in A3C.
Each worker has local train and local test to know how well it is and contribute to the neural network.
Once the experience of the workers is enough(about 500 iterations), we will use the value and policy based to update the global network.
Note that in A3C, we will use both value based and policy based to update global network value and policy.
Result
Conclusion on A3C
A3C is a CPU based algorithms, using far less resource than many massive method.
By asynchronously launching more workers, you are essentially going to collect as much more training data, which makes the collection of the data faster.
Since every single worker instance also has their own environment, you are going to get more diverse data, which is known to make the network more robust and generates better results! No behavior replay, so no need much resource.
Conclusion
In this long blog, we know basic machine learning and learn how to apply reinforcement learning method through Flappy Bird and Mario games. In NeurIPS 2020, the paper about reinforcement learning increase in both quantity and quality, more ideas about model actor-critic, q-learning are presented. Reinforcement learning is an interesting and promising way in the future.
Extend the problem
In robotics — to efficiently find a combination of electrical signals to steer robotic arms (to perform an action) or legs (to walk)
In manufacturing — robots for package transportation or for assembling specific parts of cars
In military — among others for logistics and to provide automatic assistance for humans in analyzing the environment before actions
In inventory management — to reduce transit time and space utilization, or to optimize dispatching rules Power systems — to predict and minimize transmission losses
In the financial sector — for instance in the trading systems to generate alpha or to serve as an assistant to allow traders and analysts to save time
Steering an autonomous helicopter
For complex simulations — e.g. robo soccer
In marketing — for cross-channel campaign optimisation and to maximize long-term profit of a campaign
AdTech — optimizing a strategy of pricing Ads in order to maximize returns within a given budget
Energy management optimization — reducing data center energy cost by 40%!
I'm Trinh Nguyen, a passionate content writer at Neurond, a leading AI company in Vietnam. Fueled by a love of storytelling and technology, I craft engaging articles that demystify the world of AI and Data. With a keen eye for detail and a knack for SEO, I ensure my content is both informative and discoverable. When I'm not immersed in the latest AI trends, you can find me exploring new hobbies or binge-watching sci-fi
As a matter of fact, financial firms are under increasing pressure to do more with less. They demand faster closes, more accurate reporting, and deeper insights without proportional increases in budget or headcount. This growing gap between expectations and resources is forcing finance leaders to carefully consider how time and effort are really being spent. […]