
Language models have all developed significantly in recent years, intending to give people a more brilliant language tool. And by the end of 2022, ChatGPT was born, bringing completely new experiences to users and marking a milestone in the development of artificial intelligence in the language field.
So, what is ChatGPT, and how does it work? This article will briefly present the details related to this language model to help tech and non-tech readers understand the most basic concepts.
Without further ado, let’s jump in!
- What Is ChatGPT?
- What Is Large Model Language (LML)?
- How Does ChatGPT Work?
- Evaluating Performance and Training Limitations of ChatGPT
- Advantages of Using ChatGPT
- Future of ChatGPT
What Is ChatGPT?
ChatGPT stands for Chat Generative Pre-Trained Transformer. It’s developed based on Open AI’s GPT large language model. The OpenAI language models project has existed for many years, with the first model in 2018 as GPT. Not long after, GPT-2 (2018) and GPT-3 (2019) were born with many improvements in structure and processing ability, allowing these models to handle many tasks. Its language and results surprise people because the answer structures are natural and creative.


In December 2022, OpenAP optimized and launched this model with the GPT-3.5 version, the predecessor of the current model. Until now, ChatGPT supports users in many tasks based on requirements with the same quality and naturalness as human writing. So, how can this model do such tasks? Let’s study the structure and operation of Chat GPT.
What Is Large Model Language (LML)?
Models like ChatGPT, such as GPT-3 and many other language models are called large language models. Simply, large language models will input any considerable amount of text. Then the model will learn the relationship between words and their information and predict the following terms during processing. The quality of the data generated depends on the training and control of the person associated with a particular task. Those models will increase their capacity as the size of their input datasets and parameter space increase.

The core of any Large Model Language is Transformers – a neural network that learns context and thus meaning by tracking relationships in sequential data like the words in this sentence. Transformer models apply an evolving set of mathematical techniques, called attention or self-attention, to detect subtle ways even distant data elements in a series influence and depend on each other.
Thanks to this mechanism, the model can understand the information from the input text and then convert it into an output that meets the task’s requirements. For example, translating a paragraph from an original language to another one with the correct grammatical order.


How Does ChatGPT Work?
To understand how ChatGPT works, let’s analyze each step of the model’s training process. The image below shows the sequence of steps in training ChatGPT.

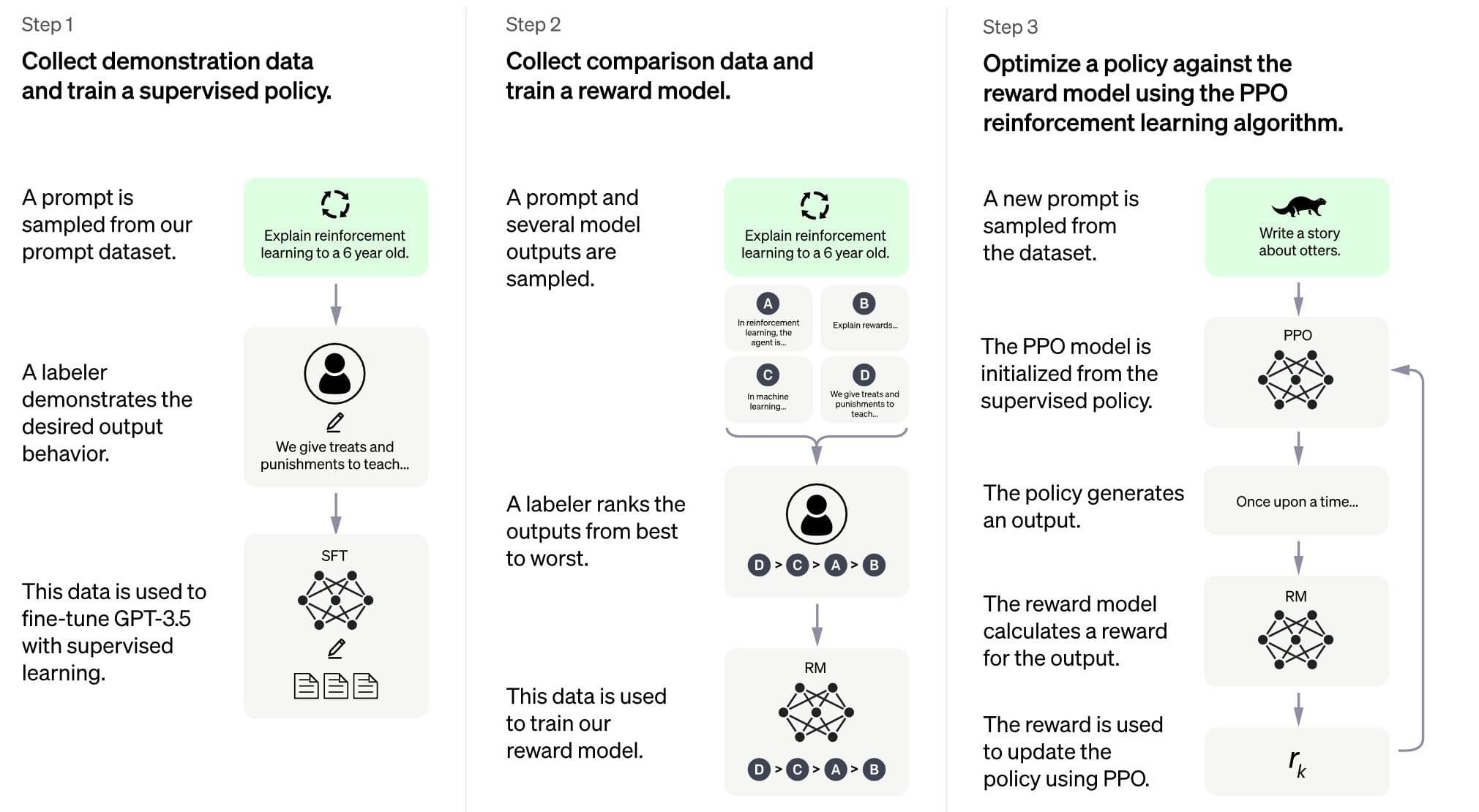
Step 1: Collect demonstration data and train a supervised policy
This process includes two parts:
Data Collection
Data collection requires most human resources to perform quality data source monitoring. The data is present in the input type (prompt) – output (the answer for the input). The prompts are collected from OpenAI data (from users or data developers) and then are matched (or labeled) with the best answers.
The system will collect up to 200 prompts from each OpenAI user to enhance data diversity. Too-long prompts and personal information will be removed entirely to ensure the confidentiality of the user. After a synthesis period, ChatGPT’s system has more than 13,000 prompts.
They divide these prompts into three categories:
- Simple and plain prompts: Any arbitrary task. Example: “Tell me about something”
- Few-shot prompts: Including several instruction-response pairs so that the system can understand the context of the question.
- User-based prompts: Taken from user data from OpenAI
During the data collection process, a huge amount of this data is divided into three broad categories.
- Direct question: “Tell me about somethings….”
- Few-shot: Give one or more examples first and then ask to complete the task
- Continuous form: Start a story or discussion and ask to continue refining the story and conversations until the end.
Model Selection
Instead of using the GPT-3 (2019) model, researchers used a more refined model called GPT-3.5 that was fine-tuned during programming.
The previous training process results in a model that can respond stably to the user’s request. But the answer’s quality is not really good and still has many errors.
To overcome this problem, instead of continuing the labeling process as above, which requires a lot of human resources and time, the labelers should evaluate answers from this model and then construct a reward model to update information for ChatGPT.
Step 2: Collect comparison data and train a reward model
This step aims to generate data to build a reward model to utilize reinforcement learning that enables an assessment to produce optimal outcomes.
The language model will process selected prompts, generating different random responses for each prompt. Labelers will rate the correctness and reasonableness of these answers from best to worst to produce the required rated dataset. The new data will help train the reward model. This model will take many responses from the language model and rank them in order of preference.
Step 3: Optimize a policy against the reward model
In this section, the language model will be given a random prompt and answer according to some rules or “policy” learned from step 2. These rules represent criteria for the reinforcement learning model to maximize its goal. Based on the reward model developed from step 2, a reward value scale is determined for each prompt-response pair. The reward is then reverted to the model to improve the criteria (policy) further.

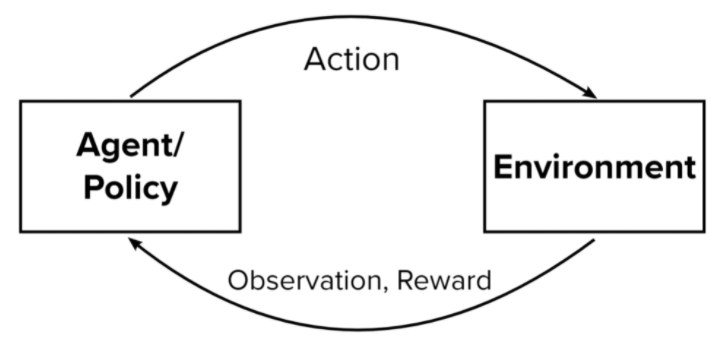
With the reinforcement learning model, Open AI uses Proximal Policy Optimization (PPO) method. Briefly explained, the PPO builds a randomly generated criteria-based algorithm, which is then trained and updated through data evaluation. This process will continuously adjust each criterion based on the answers this language model generates. This method uses some special optimization algorithms to limit some changes in the requirements if they are closely similar.
Evaluating ChatGPT’s Performance and Training Limitations
Since this language model is trained based on the dataset created by the labelers, its evaluation must also involve humans to avoid overfitting when letting the labelers evaluate. The test dataset will be taken from the OpenAI user prompts and not included in the training data.
The model will be evaluated through the highest three criteria, including:
- Usefulness: Evaluates the user’s ability to follow instructions, as well as the ability to give instructions.
- Honesty: Assess the tendency to generate false or price information with closed tasks such as Question and Answering. The model will be evaluated on a tested dataset such as TruthfulQA.
- Harmlessness: Assesses the ethical relevance of a model, avoiding content that is harmful, disrespectful, immoral, or offensive to people. The model will be evaluated on a benchmark scale with the RealTOxicityPrompts and CrowS-Pairs datasets.
However, this training method still has many apparent limitations because the training data for the model will be affected by many complex subjective factors, including:
- Labelers’ common understanding and perception platform for data generation, combined with researchers’ data requirements.
- The selection of prompts comes from OpenAI users.
- The bias of labelers in data evaluation and model outcome evaluation.
Training Limitations
This is understandable since researchers and labelers don’t represent all users of this language model. Some knowledgeable users can quickly spot errors if any, while the typical user can ignore it and assume it’s true. We can mention some of the apparent shortcomings below:
- Lack of study in training control: The research process needs some experiments to change training parameters. Therefore, it is pretty challenging to assess the improvements from the model and the performance of the reinforcement learning model from user feedback.
- Lack of ground truth data for the comparison with generated data.
- Human references are inconsistent: Each labeler has different background knowledge, so may disagree with the results from the system, leading to the potential risk of information errors for the system.
- Lack of testing for prompt stability for the reward model: There is no report evaluating the stability of prompts in terms of meanings. The main question is whether multiple prompts with the different syntax but the exact meaning will produce nearly the same results.
- Another problem: During reinforcement learning, the model sometimes generates exceptional results to optimize the reward system (over-optimized policy phenomenon). OpenAI has released an update that adds many conditions so that this phenomenon does not or less happen.
Advantages of Using ChatGPT
OpenAI trained ChatGPT in various linguistic tasks, including responding in the form of languages and handling highly complex tasks such as creating documents or developing an application. Here are 7 great apps that are of interest to most users:
- Daily Language Tasks: ChatGPT is trained on many different language tasks that people often use daily. For example, translation, text summarizing, answering questions, email writing, event or conversation summarizing, SEO Writing, blog posts, explaining the term, and more. Besides, ChatGPT can take care of some issues that require reasoning before answering.
- Content Creation: ChatGPT can support users to create any form of information, from writing poetry, writing essays, analyzing data, creating movie scripts, analytics, and writing music according to any user’s wishes. ChatGPT relies on user prompts to understand the request context, then reinvents based on that. Chat GPT will present the ideas that users want to create and offer their best options.
- Conversation: ChatGPT can chat with users in a very natural way. It can become any character when a user gives a prompt describing the characters, the tone of AI, and the conversation context.
- App Development and Optimization: ChatGPT not only works and returns language results, but it can also build basic programming applications in many languages and explain specifically how the program works. It’s trained in many different language tasks that people often use daily, such as translation, text summarizing, answering questions, and burning many other tasks. Not only that, ChatGPT can handle some issues that require reasoning before answering.
- Become Specific Tools: Users can request ChatGPT to become a search engine, an environment of the Linux operating system, some text tools such as Google Sheets, solve math questions, analytic context, and many other tools, primarily virtual assistant.



Besides various benefits, ChatGPT has a series of problems as well as some consequences for users:
Information Accuracy
This is always a problem that many users report in the ChatGPT test. With large amounts of data, some may need updating, resulting in incorrect information. Although ChatGPT can solve many simple to complex problems, it still needs to improve basic mathematical reasoning.
OpenAI has admitted that truth. It’s because the ChatGPT model is a language model that does not link to any other search engine. It analyzes the context and builds an answer based on the ability of the language to appear. Therefore, the results of ChatGPT are not reliable enough to use as a reference.
Bias in Training Dataset
This is a problem with all current language models because content quality control for metadata is too complex and takes a lot of time. Therefore, ChatGPT risks creating unethical information about gender, ethnicity, or ethnicity.
However, OpenAI has taken some measures to reduce the risk of malicious data, such as using filtering techniques to remove explicit or inappropriate language. It also implemented ongoing monitoring and evaluation processes to ensure its models perform well and do not exhibit bias or harmful behavior.
User Misuse
ChatGPT can do everything – that’s what many users say about this system. With the ability to answer most questions and a lack of user verification before collecting data, users risk becoming heavily dependent on this model instead of considering it as a support tool.
In many cases, high school students use it to complete tests, or university students use it to write dissertations or reports. These abuses bring many dire consequences, especially the recognition of unverified information.
Future of ChatGPT
ChatGPT has brought a lot of exciting benefits to many different aspects of life. Not only supporting information suggestion and processing requests, but the potential of ChatGPT is so great that Microsoft bought the whole model and put it into Windows and Bing search site applications to strongly compete with Google, which is the most prestigious search system at present.
The launch of ChatGPT also prompted many other technology firms to focus on creating language models with higher performance, more natural language representation, and the ability to do multiple tasks. Models such as Flan-T5, Meta OPT-ILM, or Meta LLaMa will train on many sets of metadata, dividing into more than 2000 different tasks.
OpenAI will not stop there. In many recent reports, OpenAI will continue to train to upgrade the core system GPT-3.5 to improve performance on many important tasks, including the accuracy and nature of the model, while also performing better for multi-languages.