Through our eyes, humans possess the incredible ability to observe, comprehend, contextualize, and interpret the world around us. Although they don’t inherently serve recording, storing, or analyzing visual data, our eyes function as remarkable, fine-tuned instruments. They allow us to identify objects, navigate uncharted environments, and unpack experiences both profound and commonplace.
Imagine having millions of eyes to position anywhere, from buildings and cars to streets, robots, satellites, etc. It’d be great if we could enjoy the sheer quantity and speed at which we could access any information we need.
And guess what? This isn’t just fantasy anymore since we already have computer vision technology, giving computers the capability to achieve a high-level understanding of digital images and videos.
What is computer vision? How does it work? What are real-life applications of computer vision?
Let’s explore everything about this exciting field in this article.
What Is Computer Vision Technology?
Computer vision is a branch of artificial intelligence (AI) that makes it possible for computers and systems to extract valuable information from digital images, videos, and other visual inputs before acting upon or making recommendations on that data. If artificial intelligence enables computers to think, computer vision helps them watch, perceive, and understand imaging data.
Here, convolutional neural networks (CNNs) are trained to develop human vision abilities. A computer vision model may also require CNN training for segmentation, classification, and detection using image and video data.
Ultimately, computer vision aims to teach machines to interpret and understand images pixel by pixel. So, technically speaking, computers will attempt to retrieve visual data, organize it, and use advanced software to analyze the results. More on the workings of computer vision technology in the next part!
Computer Vision Examples
You may not notice, but computer vision is applied frequently. Here are just a few examples of common computer vision tasks:
#1 Optical Character Recognition
OCR is among the most popular uses of computer vision systems. A notable instance is Google Translate, which can take a picture of anything – from menus to signboards – and convert it into text, which the software later translates into the user’s language of choice. We may also use OCR in various applications, such as automated highway tolling and translating handwritten documents into digital versions.
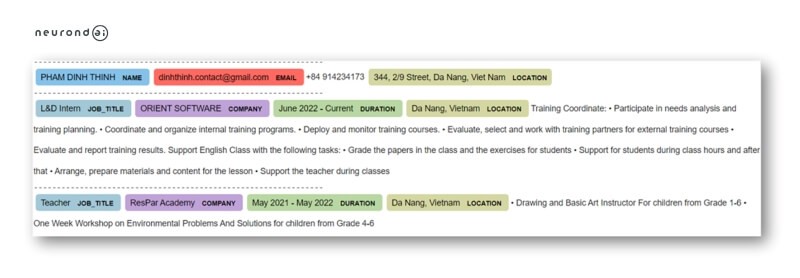
Our Dr.Parser is also a case in point. The CV parser tool helps convert candidates’ information on resumes and CVs automatically for storage or reports. HR or talent acquisition professionals no longer have to read through and extract candidate data manually, which takes time and effort. To shorten their resume screening process, Dr.Parser utilizes computer vision, including OCR and layout detection, to detect fields on resumes, such as personal information, work experience, education, etc. Besides, we apply Natural Language Processing – Name Entity Recognition and Rule-based NLP to
It takes only 2-3 seconds to parse a CV with an accuracy rate of up to >95%. Dr.Parser deals with multiple CV forms and layouts as well, including one/multiple-column resumes.
#2 Image Classification
Detect an image and then classify it. In other words, computer vision technology will accurately predict that a given image belongs to a specific class. For example, a social media company might want to apply it to recognize and remove offensive images uploaded by users automatically.
Dr.Parser is doing a great job of classifying images. As mentioned, I can detect information from searchable PDFs or Word documents. In the case of extracting data from CVs in PNG or JPG formats, this AI tool performs well with the help of the image classification technique.
#3 Object Detection
Identify a particular class of image before detecting and tabulating its appearance in an image or video. Some instances of this are recognizing defects on an assembly line or spotting machinery that needs maintenance.
#4 Object Tracking
Follow or track an object after it has been detected. This task is often carried out with images collected in sequence or real-time video feeds. Self-driving cars, for example, are required not only to identify and detect objects like pedestrians, other automobiles, and road infrastructure but also to track them in motion to prevent crashes and observe traffic regulations.
#5 Content-based Image Retrieval
Employ computer vision to browse, search, and retrieve images from huge data repositories based on the images’ content as opposed to the metadata tags associated with them. This task may include automatic image annotation as a substitute for manual image tagging. It can also be applied to digital asset management systems to improve the precision of search and retrieval.
How Does Computer Vision Work?
A computer vision system is made up of two key elements: a sensing device like a camera and an interpreting gadget, e.g., a computer. The sensory device collects visual input from the environment, which the interpreting machine processes to derive meaningful information.
Computer vision algorithms are also an essential part of computer vision, founded on the concept that “our brains depend on patterns to decode individual objects.” Just as human brains process visual input by seeking patterns in the shapes, colors, and textures of things, computer vision algorithms analyze pictures by identifying patterns in the pixels that constitute the image. These patterns may detect and categorize various objects in the photo.
To analyze an image, a computer vision algorithm first turns the picture into numerical data that the computer can process. It divides the image into a grid of small parts known as pixels and assigns each pixel a set of numerical values that define its color and brightness. These values can eventually be utilized to produce a digital version of the image that computers can understand.
After converting the image to numerical data, the computer vision algorithm analyzes it. This mainly involves employing machine learning and artificial intelligence techniques to discover patterns in image data and draw decisions based on those patterns. An algorithm, for example, may examine the pixel values in an image to identify the objects’ borders and to distinguish specific patterns/ textures.
Overall, computer vision aims to help machines analyze and comprehend visual data in a manner comparable to that of human eyes and brains, thereby making informed decisions.
Real-world Applications of Computer Vision by Industry
Computer vision applications are present in a variety of fields. Markets and Markets estimated that the global market of computer vision systems would be worth $172 billion in 2023 and reach $45.7 billion by 2028.
Below are some popular computer vision applications in transportation, manufacturing, and healthcare.
1. Transportation
Autonomous Vehicles
Autonomous vehicles are no longer fiction, yet right now, thousands of developers and engineers are working to make self-driving cars safer and more reliable to users.
Regarding this computer vision application, its key tasks include the creation of 3D maps, motion estimates, object detection, and classification (e.g., traffic lights and road signs). Besides, they also use cameras and sensors to gather information about their environment, analyze it, and make appropriate decisions.
Other computer vision techniques that researchers working on the ADAS technology (Advanced driver-assistance system) recommend are pattern recognition, feature extraction, object tracking, and 3D vision, which seek to help build real-time algorithms supporting driving operations.
Vehicle Classification
There is a long history of use cases for automatic vehicle classification. Over the years, technology for this computer vision application has advanced dramatically. Deep learning technologies enable the implementation of large-scale traffic management systems, which incorporate conventional and low-cost security cameras.
Now, vehicles can be recognized, tracked, and categorized across multiple lanes using modern, affordable sensors such as closed-circuit television (CCTV) cameras, light detection and ranging (LiDAR), and thermal imaging devices.
Furthermore, computer vision solutions relying on deep learning have also been seen in the construction field. They recognize construction vehicles for safety monitoring, productivity evaluation, and managerial decision-making.
Moving Violations Detection
To curb reckless driving, law enforcement organizations and local governments have ramped up the use of camera-based traffic surveillance systems. The identification of stopped cars in unsafe spaces is arguably the most important application here.
Additionally, computer vision techniques are being applied more often in smart cities to automate the intelligent detection of violations like speeding, running stop signs or red lights, driving the wrong way, making illegal turns, etc.
Automated License Plate Recognition
Retrieving license plate information from still photos or videos is a crucial component of many contemporary public safety and transportation systems. As a result of automated license plate recognition (ALPR), the transportation and public safety sectors have seen many positive changes.
Modern tolled roadway solutions are made possible by such number plate recognition systems, which also offer significant operational cost reductions through automation and even open doors for entirely new market opportunities like police cruiser-mounted license plate reading units.
OpenALPR is a well-known automatic number plate recognition library that uses optical character recognition on pictures or video feeds of license plates from moving cars.
Apart from these four use cases in the transportation field, computer vision plays an increasingly important role in pedestrian detection, parking occupancy detection, infrastructure asset inspection, intelligent transportation systems, automatic crack detection on roads, road maintenance allocation efficiency, and more.
2. Manufacturing
Defect Inspection
Large-scale manufacturing facilities often have trouble detecting flaws in their produced goods with 100% accuracy.
Camera-based systems gather data in real-time, evaluate it using computer vision and machine learning algorithms, and then compare the results to predetermined quality control standards.
All this makes it easier to find both large- and small-scale production line defects, thereby minimizing expenses and boosting error-free production.
Take our Athena project as an example. The client wants to figure out cracks or discontinuities in the object’s edges. To achieve this, we applied advanced technologies for defect detection in X-ray images, such as mask RCNN neural networks, Edge detection, and thresholding.
Reading Text and Barcodes
Given that most products come with barcodes on their packaging, it’s now possible to automatically detect, validate, convert, and translate barcodes into readable text. Simply apply one computer vision technology called optical character recognition.
Through OCR, text is retrieved from photographed labels and packaging and cross-referenced with databases.
This process assists in tracking packages at every stage of product development, identifying products with incorrect labels, and providing information about expiration dates, product quantities in magazines, and beyond.
Product Assembly
Big corporations worldwide have already adopted automation for their product assembly lines. Tesla reported to have automated over 70% of their manufacturing processes.
Here, computer vision supports in many ways, from creating 3D models to guiding robots and human workers, tracking product components, and maintaining packaging standards.
Visual Inspection of Equipment
One important tactic in the smart manufacturing industry is computer vision for visual inspection. Vision-based inspection systems become popular for automated inspection of PPE (personal protective equipment), like mask and helmet detection.
On building sites or in a smart factory, computational vision is beneficial for adhering to safety procedures.
3. Healthcare
X-Ray Analysis
Computer vision has proven helpful in medical X-ray imaging for planning surgeries, magnetic resonance imaging (MRI) reconstruction, research, and treatment.
While most doctors still use manual X-ray image analysis to diagnose and treat ailments, computer vision can automate the process, enhancing efficiency and accuracy.
Plus, modern image recognition algorithms can identify patterns in X-ray images that the human eye may fail to recognize.
CT and MRI
Computer vision is also widely applied in the analysis of computed tomography (CT) scans and MRI.
These systems are crucial for enhancing patient outcomes. Artificial intelligence systems can evaluate radiological images with the same accuracy levels as human doctors, while deep learning algorithms help boost the resolution of MRI and CT scans. Automation improves accuracy since machines are now able to detect subtleties that are imperceptible to the human eye.
In addition, thanks to computer vision analysis of CT and MRI data, doctors can identify tumors, internal bleeding, blocked blood vessels, and other potentially fatal conditions more easily and rapidly via automated detection. Breast and skin cancer detection has already benefited from the effective use of image recognition. To be more specific, by comparing malignant and non-cancerous cells in medical imaging data, image recognition enables medical professionals to discern anomalies and changes quickly and then classify them as malignant or benign.
Blood Loss Measurement
One of the leading causes of infant mortality is postpartum hemorrhaging. In the past, doctors could only estimate the amount of blood lost by a patient during childbirth. However, with computer vision, doctors are now able to measure blood loss in childbirth. They analyze surgical sponges and suction canister images using AI-powered tools.
Among the institutions that used this technique was the Orlando Health Winnie Palmer Hospital for Women and Babies. Research also revealed that most of the time, doctors overestimate how much blood a patient loses during child delivery.
As a result, computer vision makes it possible to detect blood loss more precisely. This allows healthcare workers to treat patients with greater efficiency.
Movement Analysis
Computer vision and deep learning models also do a good job of identifying neurological and musculoskeletal diseases without a doctor’s assessment. For instance, impending strokes, balance issues, and gait abnormalities.
For example, Pose Estimation computer vision applications help doctors diagnose patients quickly and accurately by analyzing a patient’s movements. Most estimating human pose methods are geared toward adults. Meanwhile, this computer vision technique has been deployed in medical infant motion analysis. Medical professionals can observe and evaluate the natural movements of the baby to detect neurodevelopmental abnormalities in infants at a very young age and take necessary action. Furthermore, when employing an automated motion analysis system, infant body movements can be captured. Then, they can identify abnormalities far more efficiently.
Applying Computer Vision Technology
Computer vision is a game-changing technology with many fascinating applications. It can be implemented successfully in numerous industries relying on image or video data. Transportation, healthcare, and the manufacturing industry, to name a few. Google, Facebook, Apple, and Microsoft heavily investing in the computer vision field. And it’s just a matter of time before dominating the worldwide AI-based market.
Unfortunately, most companies and governments still struggle to fund individual computer vision labs to construct complete models. That’s when Neurond AI steps in with our unrivaled computer vision expertise.
At Neurond AI, we provide end-to-end consultation services from strategy formulation to product launch. With proven expertise, we’re committed to delivering the best-tailored solutions that can convert only valuable information from visual input. Undoubtedly, our deep learning-powered solutions will significantly cut the time your business takes on manual data extraction.
I'm Trinh Nguyen, a passionate content writer at Neurond, a leading AI company in Vietnam. Fueled by a love of storytelling and technology, I craft engaging articles that demystify the world of AI and Data. With a keen eye for detail and a knack for SEO, I ensure my content is both informative and discoverable. When I'm not immersed in the latest AI trends, you can find me exploring new hobbies or binge-watching sci-fi
As a matter of fact, financial firms are under increasing pressure to do more with less. They demand faster closes, more accurate reporting, and deeper insights without proportional increases in budget or headcount. This growing gap between expectations and resources is forcing finance leaders to carefully consider how time and effort are really being spent. […]