In this article, we demonstrate the efficacy of transfer learning automatic speech recognition (ASR) tasks. We start with a pre-trained English ASR model and show that transfer learning can be effectively and easily performed in a different language (for example, Vietnamese), even if the dataset for fine-tuning is small.
Index Terms – Vietnamese, automatic speech recognition, transfer learning, text to speech Vietnamese
Introduction
In the last few years, end-to-end (E2E) neural networks (NN) have achieved new state-of-the-art (SOTA) results on many automatic speech recognition tasks (ASR). Such models replace the traditional multi-component ASR system with a single, end-to-end trained NN that directly predicts character sequences. Therefore, it greatly simplifies training, fine-tuning, and inference.
But, E2E training of ASR models requires large datasets and heavy compute resources. There are more than 5,000 languages around the world, but very few languages have large enough datasets to train high-quality ASR models. Vietnamese is one of these few languages that have a very small dataset.
The motivation of this work is to implement Vietnamese language ASR from the pre-trained English model (QuartzNet 15×5).
Anderson et al applied this idea to acoustic modeling using the International Phonetic Alphabet (IPA). The cross-language acoustic model adaptation was explored in depth in the GlobalPhone project. It was based on two methods: (1) partial model adaptation for languages with limited data, and (2) boot-strapping, where the model for a new target is initialized with a model for another language and then completely re-trained on the target dataset.
Hybrid Deep Neural Network (DNN) – HMM models also made use of TL. Basically, the features learned by DNN models tend to be language-independent at low layers. So, all languages can share these low-level layers.
This hypothesis was experimentally confirmed by TL between ASR models for Germanic, Romance, and Slavic languages. Kunze et al applied TL to DNN-based end-to-end ASR models and adapted an English ASR model for German. In their experiments, they used a Wav2Letter model and froze the lower convolutional layers while retraining the upper layers.
Similarly, Bukhar et al adapted a multi-language ASR model for two new low-resource languages (Uyghur and Vietnamese) by retraining the network’s last layer. Tong et al trained a multilingual CTC-based model with an IPA-based phone set and then adapted it for a language with limited data.
They compared three approaches for cross-lingual adaptation: (1) retraining only an output layer; (2) retraining all parameters; (3) randomly initializing weights of the last layer and then updating the whole network. They found that updating all the parameters performs better than only retraining the output layer.
Model Architecture
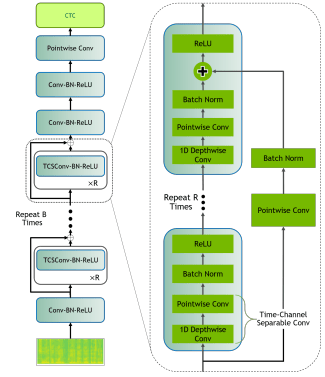
Our experiments use a QuartzNet model trained with Connectionist Temporal Classification (CTC) loss. QuartzNet employs 1D time-channel separable convolutions, a 1D version of depthwise separable convolutions. Each depthwise separable convolution module is made up of two parts: a depthwise convolutional layer and a pointwise convolutional layer.
Depthwise convolutions apply a single filter per input channel (input depth). Pointwise convolutions are 1 × 1, helping create a linear combination of the outputs of the depthwise layer. BatchNorm and ReLU are applied to the outputs of both layers.
Each 1D time-channel separable convolution block can be separated into a 1D convolutional layer with kernel length K. It operates on each channel separately across K time frames and a point-wise convolutional layer that runs on each time frame independently across all channels.
QuartzNet models have the following structure: start with a 1D time-channel separable convolutional layer C1 followed by a sequence of blocks (see Figure above). Each block Bi is repeated Si times and has residual connections between each repetition. Each block Biconsists of the same base modules repeated Ritimes.
The base module contains four layers:
1) Ksized depthwise convolutional layer with C channels
2) a pointwise convolution
3) a normalization layer
4) ReLU
The last part of the model consists of one additional time-channel separable convolution (C2), and two 1D convolutional layers (C3, C4). The C1 layer has a stride of 2, and C2 layer has a dilation of 2.
There are five unique blocks: B1 – B5, and each block is repeated S = 3 times (B1 – B1 – B1 − … – B5 – B5 – B5).
A regular 1D convolutional layer with kernel size K, cin input channels, and cout output channels have K × cin× coutweights. The time-channel separable convolutions use K × cin+ cin× coutweights split into K × cin weights for the depthwise layer and cin × cout for the pointwise layer.
Dataset
The dataset we use in this article is the VIVOS dataset, which contains a speech corpus by recording speech data from more than 50 native Vietnamese volunteers.
For training, 46 speakers (22 males and 24 females) help record 15 hours of speech with 11,660 utterances. While for testing, another set of 19 speakers (12 males and 7 females) recorded 50 minutes of speech with 760 utterances in total.
This dataset has two features:
Audio files in .wav
Text file that contains all the transcriptions of audio files.
Walk-through The Code
We recommend using Google Colab for this training section. But if you have all the dependencies and GPU, you can run it in your local.
First, open a new Python 3 notebook and follow the instructions below.
Now that we have a processed dataset, we can begin training an ASR model on this dataset. The following section will detail how we prepare a CTC model which utilizes a Character Encoding scheme.
This section will utilize a pre-trained QuartzNet 15×5, trained on roughly 7,000 hours of English speech base model. We will modify the decoder layer (thereby changing the model’s vocabulary).
If the amount of training data or available computational resources is limited, it might be useful to freeze the encoder module of the network and train just the final decoder layer. This is also useful in cases where GPU memory is insufficient to train a large network, or the model might overfit due to its size. I recommend not doing it in Vietnamese because the vocal of Vietnamese and English speaker is very different. So we need to train its encoder also.
if freeze_encoder:
char_model.encoder.freeze()
char_model.encoder.apply(enable_bn_se)
logging.info("Model encoder has been frozen, and batch normalization has been unfrozen")
else:
char_model.encoder.unfreeze()
logging.info("Model encoder has been un-frozen")
Setting up Augmentation
Remember that the model was trained on several thousands of hours of data, so the regularization provided to it might not suit the current dataset. We can easily change it as we see fit.
Note: For low-resource languages, it might be better to increase augmentation via SpecAugment to reduce overfitting. However, this might, in turn, make it too hard for the model to train in a short number of epochs.
## Uncomment lines below if you want augment your data
# with open_dict(char_model.cfg.spec_augment):
# char_model.cfg.spec_augment.freq_masks = 2
# char_model.cfg.spec_augment.freq_width = 25
# char_model.cfg.spec_augment.time_masks = 2
# char_model.cfg.spec_augment.time_width = 0.05
char_model.spec_augmentation =
char_model.from_config_dict(char_model.cfg.spec_augment)
Setup Metrics
Originally, the model was trained on an English dataset corpus. When calculating Word Error Rate, we can easily use the “space” token as a separator for word boundaries. On the other hand, certain languages such as Japanese and Mandarin do not use “space” tokens, instead opting for different ways to annotate the end of the word.
In cases where the “space” token is not used to denote a word boundary, we can use the Character Error Rate metric instead, which computes the edit distance at a token level rather than a word level.
We might also be interested in noting model predictions during training and inference. As such, we can enable logging of the predictions
And that’s it! We can train the model using the Pytorch Lightning Trainer and NeMo Experiment Manager, as always.
For demonstration purposes, the number of epochs is kept intentionally low. Reasonable results can be obtained in around 100 epochs (recommend 1,000 epochs for a better result if you have a GPU or Google Colab pro/pro+ account).
import torch
import pytorch_lightning as ptl
if torch.cuda.is_available():
accelerator = 'gpu'
else:
accelerator = 'cpu'
EPOCHS = 50 # 100 epochs would provide better results, but would take an hour to train
trainer = ptl.Trainer(devices=1,
accelerator=accelerator,
max_epochs=EPOCHS,
accumulate_grad_batches=1,
enable_checkpointing=False,
logger=False,
log_every_n_steps=5,
check_val_every_n_epoch=10)
# Setup model with the trainer
char_model.set_trainer(trainer)
# Finally, update the model's internal configchar_model.cfg =
char_model._cfg
# Environment variable generally used for multi-node multi-gpu training.
# In notebook environments, this flag is unnecessary and can cause logs of multiple training runs to overwrite each other.os.environ.pop('NEMO_EXPM_VERSION', None)
config = exp_manager.ExpManagerConfig(
exp_dir=f'experiments/lang-{LANGUAGE}/',
name=f"ASR-Char-Model-Language-{LANGUAGE}",
checkpoint_callback_params=exp_manager.CallbackParams(
monitor="val_wer",
mode="min",
always_save_nemo=True,
save_best_model=True,
),
)
config = OmegaConf.structured(config)
logdir = exp_manager.exp_manager(trainer, config)
Let’s Train
%%time
trainer.fit(char_model)
You can visit here to refer to the full notebook for more details and information.
Result and Conclusion
We have tried several voice records in .wav format and got a good result. However, it still maintains some weaknesses:
The model predicted not very well on different vocals not included in the dataset.
It still can’t be ready for real-time ASR because of a very small dataset (about 15 hours of audio) respectively to its pre-trained datasets (roughly 7000 hours of English audio).
A transfer learning approach based on reusing a pre-trained QuartzNet network encoder turns out to be very effective for various ASR tasks. In all our experiments, we observed that fine-tuning a good baseline performs good results on a small dataset and small model.
We introduce this method to implement Vietnamese Automatic Speech Recognition (ASR) using QuartzNet 15×5 model. This model was based on a deep neural network with 1D time-channel separable convolutional layers. The small model (about 18,9M parameters) opens new possibilities for speech recognition on mobile and embedded devices.
I'm Trinh Nguyen, a passionate content writer at Neurond, a leading AI company in Vietnam. Fueled by a love of storytelling and technology, I craft engaging articles that demystify the world of AI and Data. With a keen eye for detail and a knack for SEO, I ensure my content is both informative and discoverable. When I'm not immersed in the latest AI trends, you can find me exploring new hobbies or binge-watching sci-fi
In today’s fast-paced world, we’re constantly multi-tasking and looking for ways to optimize our time. Spending hours reading long documents or articles can be time-consuming for many people, especially if they have other tasks to accomplish. This is where Microsoft Word’s text-to-speech feature comes in handy. It allows you to read your document aloud so […]